


5分钟看懂GPT系列演进过程
技术总结专栏
作者:瑶光
GPT1到Instruct GPT,呈现参数量越来越大,下游训练任务越来越无边界的趋势。
GPT1
论文:Improving Language Understanding by Generative Pre-Training
基本思路:生成式预训练+判别式任务精调
生成式预训练(无监督):在大规模文本数据上训练一个高容量的语言模型,从而学习更加丰富的上下文信息。
判别式任务精调(有监督):将预训练好的模型适配到下游任务中,并使用有标注数据学习判别式任务。
模型结构:基于transformer的单向语言模型,这一点有别于BERT这种双向语言模型 。参数量117M(BERT 345M)
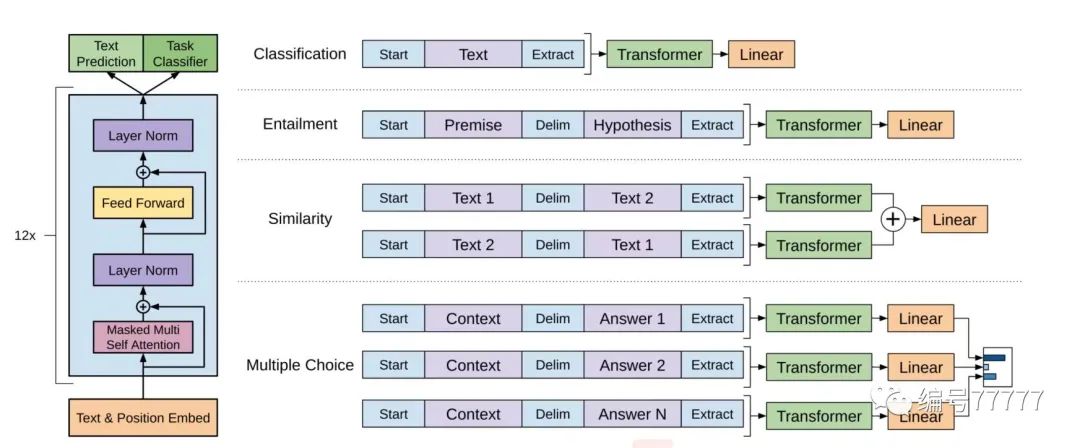
总结:GPT1的思路还比较中规中矩:海量数据预训练+下游任务精调
GPT2
论文:Language Models are Unsupervised Multitask Learners
基本思路:去掉有监督,只保留无监督学习
举例:实现翻译任务,训练数据中构造"中文句子=英文句子",推理时用"中文句子=",通过greedy decoding取第一个句子作为翻译结果。
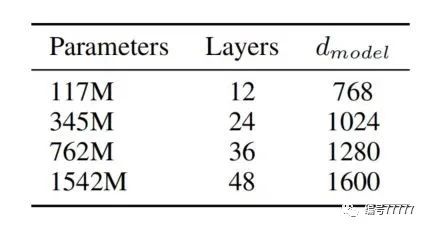
模型结构:layer norm放在子模块的输入处,就是在最后一个 self-attention 模块后面增加layer norm。最终提供了四种参数量的模型。
总结:GPT2开始有“万径归一”的感觉了,虽然说看上去只是很多任务混在一起训,但是不再需要专门定义任务专门finetune,打破了各个任务人为划分的边界。
GPT3
论文:Language Models are Few-Shot Learners
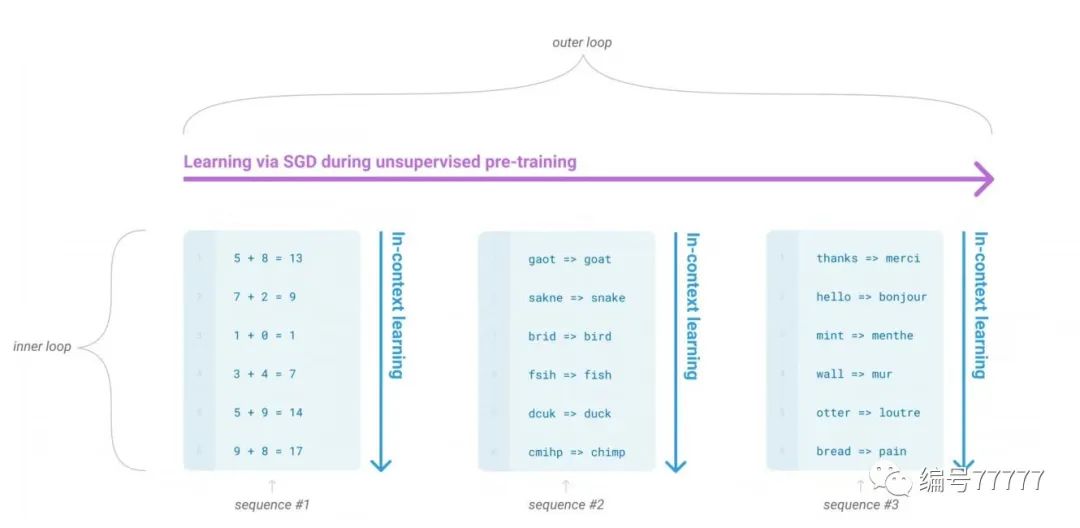
基本思路:无监督学习+in-context learning
few-shot(fs). 推理的时候给一些声明作为条件,但是不更新权重。声明的样本量大约是10到100(因为上下文视野是2048)。除了这些例子,还有一个想要模型回答的问题。简单来说就是给一个问题的描述,给几个这样的例子,最后给一个类似的问题让模型回答。比如:问题描述:把英语翻译成中文。例子1:one->一。例子2:two->二。问题:three->
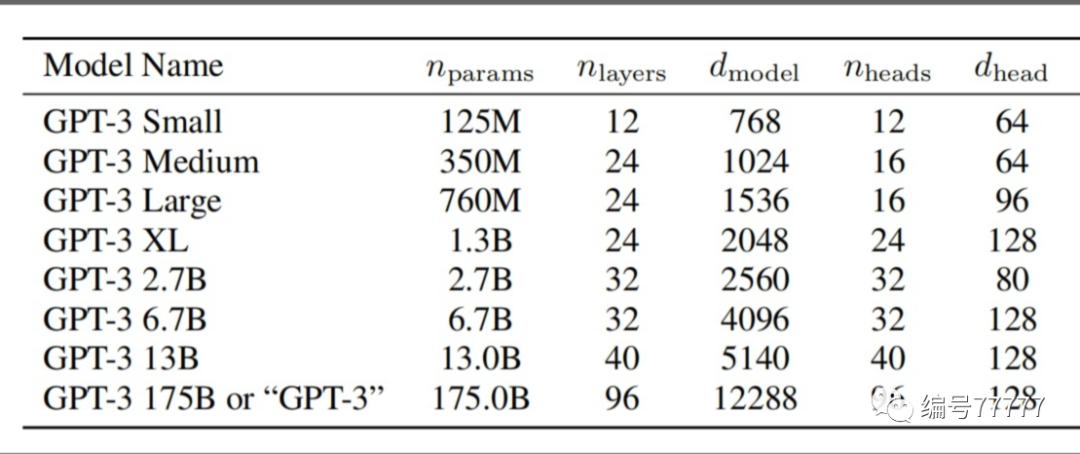
模型结构:一共有八种参数量的模型。我们将规模最大的模型称为 GPT-3,模型参数量为 1750 亿。
总结:GPT3 明确引入了in-context learning,引导模型在不需要改变参数的情况下给出想要的回答。类似于引导模型推理的方向。但如果是没见过的in-context,模型还能像人一样推理吗?
"Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? " 这篇文章认为:in-context learning中,模型学到(激活)了输入数据、预测标签的分布,以及这种数据+label的语言表达形式。
Instruct GPT
论文:Training language models to follow instructions with human feedback
基本思路:
先获取一个gpt3预训练模型( 175B )。
第一步:找人标一堆数据(demonstration data),finetune gpt3。举例:输入是一个提问:向一个六岁孩子解释登月。人类标记员标记想要的答案作为输出。
第二步:取一堆模型的输出,然后让人评分。利用这些评分,学一个打分模型(reward model)。
第三步:利用增强学习(ppo),根据第二步中的打分模型优化模型。
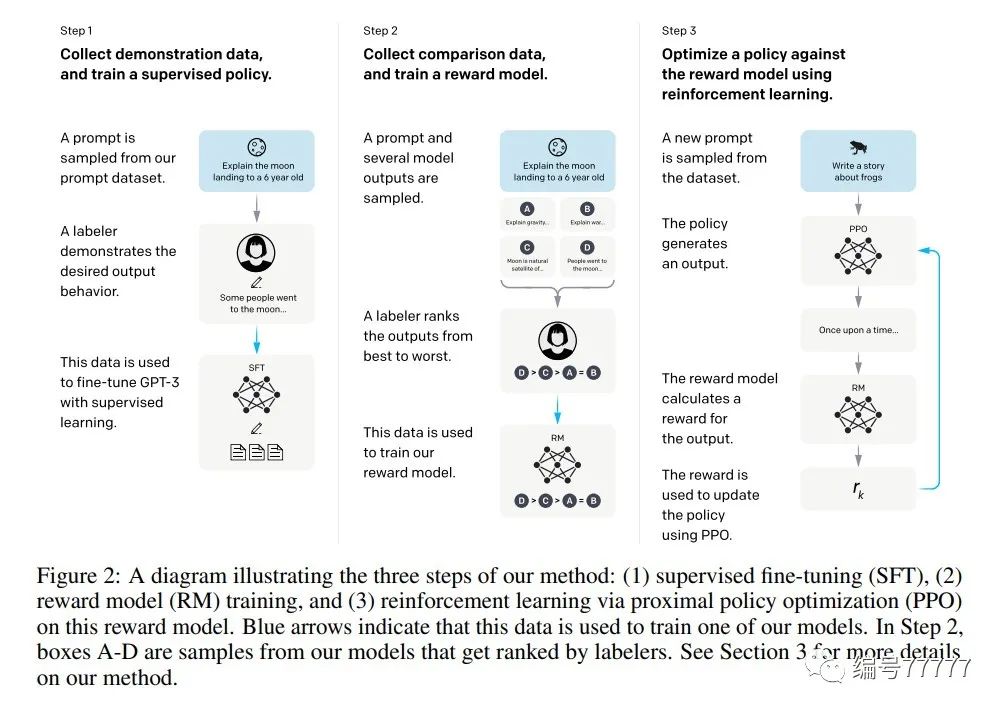
模型结构:有三种模型规模:13亿、60亿和1750亿参数。
总结:Instruct GPT直接上人工标注,算是有多少智能就有多少人工。
本篇文章来源于微信公众号: walle优选笔记
