


ChatGPT 原理探索
前言
ChatGPT的强大程度相信很多同学都已经体验过了,无论是编写文章,问答,写代码展现除了非常惊艳的能力。一定喜欢技术的同学一定好奇,ChatGPT是如何做到“全知全能”,即会写文章,又会表达总结,精通各国语言翻译,写代码,改bug,你甚至可以提前用自然语言给他设计一些"预设"或者"情景"专注于某些任务,比如「你是一个Linux终端,运行并输出我提供给你的命令。」,「你现在是一名前端面试官,出一些问题考察我的前端知识。」。实现这些技术背后的原理是什么?本篇文章将带你从NLP相关原理出发,带你了解ChatGPt背后实现的原理。
NLP技术
NLP全称自然语言处理(Natural Language Processing)技术,它是一种人工智能技术,旨在解决计算机和人类语言之间的交互问题。NLP技术的目标是让计算机能够理解、分析、处理、生成和对话自然语言。
人机交互优化:理解输入文本的内容,提炼出其中关键信息,并作为其他应用的上游输入(比如小米小爱印象语音控制空调,高德地图语音配置导航)。 生成式任务:理解用户输入的信息,经过内部或者外部整理匹配后整理生成用户想知道的信息。(比如智能问答,智能客服,高级一些的就是写作文,写代码) 翻译:将一国语言转为另一国语言,并且翻译地尽可能通顺自然符合语境习惯。 信息摘要提取聚合:根据文章内容,标题等自动进行分类,推荐。比如知乎,小红书的首页信息流。互联网公司常用的风控算法。
ChatGPT集成了很多NLP中处理领域如文本的理解、分析、处理、生成,从产品形态上对用户非常友好易用。ChatGPT这类大模型技术的出现可能会代替了很多细分领域的NLP研究。
基于生成式的语言模型
目前处理效果比较好的NLP大语言模型,如GPT或者Bert,可以理解为基于词汇概率统计的深度建模。生成文本时,通过前面单词,来预测后面生成的内容。下图举了一个简单的例子,输入"你好",由语言模型进行补全,假设后续候选文字有"吗","像","美","不", "太"这几个字可以选择,"美", "吗"是继续生成文本时概率最高的候选词。机器学习的算法,就是在上下文环境中对候选词概率进行建模,来生成可读的文本。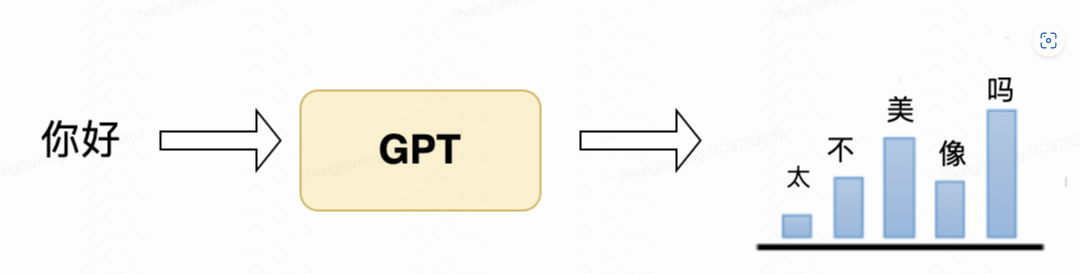
常见的例子还有我们日常使用搜索引擎中的下拉提示框:
以及我们天天使用的输入法候选,如果只使用单词联想来打字,说不定也可以得到一句话:
我们用数学化公式的方式描述一下上面的过程,假设我们有一个当前词汇w1,要预测w2,那就是期望p(w1|w2) 发生的概率最大化。在w1和w2的基础上预测w3,也就是计算p(w3|w1, w2)的概率。每一个词wi的概率都是由它的i-1项及之前所有的项决定的。如果一句话有n个词,那么就是一系列条件概率的乘积:
通过对词汇每个位置发生概率进行建模,那么就可以得到一个语言模型。上述公式可以作为机器学习的目标公式。由于概率的乘积很容易得到一个非常小的数字,容易产生溢出,因此可以取对数将乘法计算转换为加法计算,最大化以下公式的结果:
这个公式也可以理解为让机器算法利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值(既最大似然)。
深度学习使GPT学会语言技能
ChatGPT是基于深度学习技术对语言进行深度建模。将海量文本数据输入模型,他会自动学习文本数据中主谓宾结构,对于代码可以自动学习AST结构。
深度学习是什么?
深度学习是一种机器学习算法,其基于人工神经网络和深度神经网络的思想,可以有效地解决包括图像和语音识别、自然语言处理、机器翻译和预测等任务。 深度学习的核心思想是利用多层神经网络对数据进行端到端的学习和特征提取,并自动优化网络参数以最大化模型的预测准确率。深度学习的主要优点是,它可以处理大量、复杂的数据,并提取出数据中的关键特征,从而让模型在不同的任务中表现出色。 深度学习的应用非常广泛,如计算机视觉、语音识别、自然语言处理、人工智能等领域,在图像分类、目标检测、语音合成、自然语言生成等任务中,深度学习已经取得了很多突破性进展。 基于深度学习,语言模型可以自己学会文法关系比如主谓宾,编程语言中AST结构,以及真实世界中的知识。
详解GPT字母中的缩写
GPT,全称Generative Pre-trained Transformer ,中文名可译作生成式预训练Transformer。对三个关键词分别进行解读:
Generative生成式。GPT是一种单向的语言模型,也叫自回归模型,既通过前面的文本来预测后面的词。训练时以预测能力为主,只根据前文的信息来生成后文。与之对比的还有以Bert为代表的双向语言模型,进行文本预测时会结合前文后文信息,以"完形填空"的方式进行文本预测。
输入:Today is a [MASK] day 预测:good 输入:Today is a___ 预测:good day 自回归模式(Autoregressive) 双向(Bidirectional) Pre-trained:预训练让模型学习到一些通用的特征和知识。预训练的Bert通常是将训练好的参数作为上游模型提供给下游任务进行微调,而GPT特别是以GPT3超大规模参数的模型则强调few-shot, zero-shot能力,无需下游微调即可直接使用(如ChatGPT,无需进行额外参数调整即可满足各种任务需求)
Transformer:Transformer是一种基于编码器-解码器结构的神经网络模型,最初由Google在2017年提出,用于自然语言处理(NLP)领域。Transformer是一种基于自注意力机制(self-attention mechanism)的模型,可以在输入序列中进行全局信息的交互和计算,从而获得比传统循环神经网络更好的长距离依赖建模能力。后文会介绍Transfomer以及自注意力相关机制。
GPT分别经过若干个版本的改进,包含了训练方式,强化学习的加入。以及指数级增长的训练参数量:
| 版本 | 特性 | 参数规模 |
|---|---|---|
| GPT1 | GPT初始版本,2018年发布,采用了Transfomer架构中decoder部分 无监督学习以及有监督训练,下游可针对不同任务进行微调 | 1.17 亿 5GB训练数据 |
| GPT2 | GPT第二个版本,2019年发布,采用了Transfomer架构中decoder部分 强化无监督学习能力,提出了FewShot少样本学习思想,希望模型自己能够理解输入的任务并执行 | 15 亿 40GB训练数据 |
| GPT3 | GPT第三个版本,2020年发布,2019年发布,采用了Transfomer架构中decoder部分 沿用GPT2的架构,区别在于超大规模训练量(钞能力) | 1,750 亿 45TB训练数据 |
| GPT3.5(ChatGPT) | GPT3基础上引入更多的对话,代码训练数据。 GPT3基础上增加了InstructGPT强化学习机制。引入了人工标记以及奖励模型机制,使得模型有能力根据人类提示下生成符合人类偏好的文本,而不是漫无目的,不符合聊天场景的文本。 | 基于GPT3,仍然为1,750 亿 45TB训练数据 |
参数规模从下图可以看出,OpenAI的GPT3(右上角)参数规模遥遥领先其他模型: 
GPT以及GPT2主要是基于深度学习对语言模型进行建模,并提出了few-shot概念,到了GPT3,除了使用了更大规模的参数对语言模型进行建模外,还引入了强化学习机制InstructGPT调整模型的输出,使得模型可以理解并执行人类给出的任务。
零样本,单样本,少样本学习
传统语言模型中,通常的做法是在一个预训练模型通过微调来适应不同的下游任务。在GPT中提出了「少样本学习(Few-Shot)」概念。模型利用Transformer技术,可以通过大量重复任务识别到子任务处理模式,进行In Context Learning(图一)。训练完毕后用几个示例提示给模型作为条件,在不对模型参数进行更新前提下完成示例所给的任务(图二)。如下图所示,对于一个典型的数据集,一个示例有一个上下文和一个期望的完成结果(例如英语句子和法语翻译),少样本学习的工作方式是给出K个上下文和完成结果的示例,然后给出一个上下文的最终示例,模型需要提供完成结果。单样本只给出一个示例,模型即可以完成任务。而零样本则是不需要给出示例,直接让语言模型执行相应任务。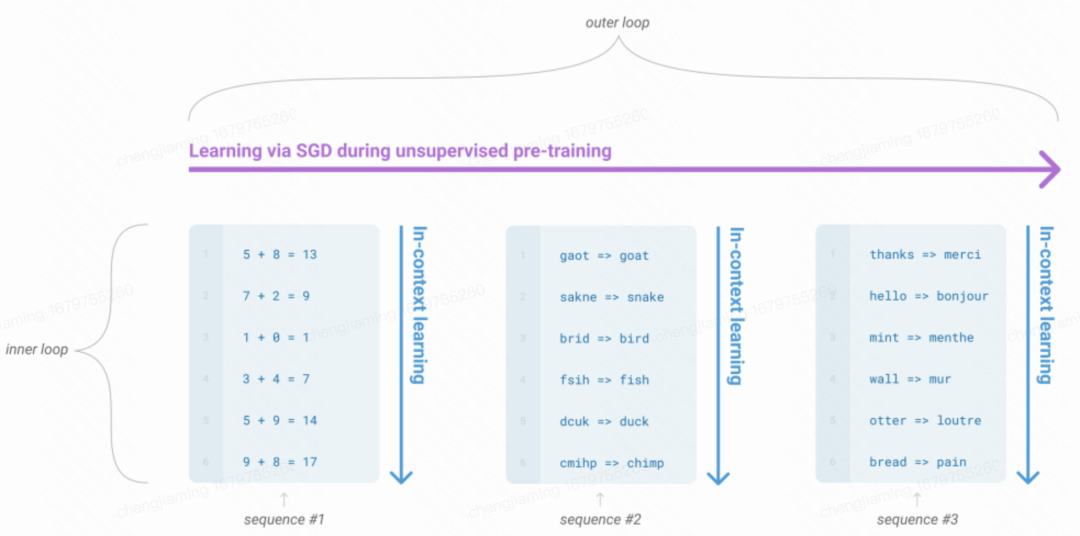
零样本,单样本,少样本之间区别,区别在于给出示例的多少。零样本是不给出示例直接让模型执行任务 
In Context Learning在大量参数上学习效果非常好,可以大大提高模型泛化能力,通过few-shot即可适应不同任务,而无需再对模型进行特定任务微调。 但是从下图中的实验数据可以发现,zero-shot零样本的能力还是比较差的,这需要通过InstructGPT技术来进行解决。
强化学习使GPT输出正确内容
什么是强化学习
强化学习(Reinforcement Learning, RL)是机器学习的一个分支,是解决智能体与环境交互的问题的一种方法。在强化学习中,智能体从环境中接收观测值并执行动作,以获得回报。强化学习的目标是通过学习如何最大化回报来使智能体在环境中做出最优的决策。 强化学习中,智能体通过与环境的交互来学习如何做出最优的决策。在此过程中,智能体需要识别当前状态、选择适当的行动以及获取最大回报。智能体根据当前状态,通过学习如何选择最佳的行动来最大化未来的回报。在强化学习中,智能体的重要任务是在不断的试错中学习如何优化回报,不断改进自己的策略。 强化学习在很多领域都得到了广泛的应用,如游戏、机器人控制、自动驾驶、语音识别等。强化学习是实现人工智能的一个重要方法,其研究和应用前景非常广阔。
AI马里奥(智能体)通过强化学习算法在游戏(环境)中不断得到反馈学习,最后习得通关技巧: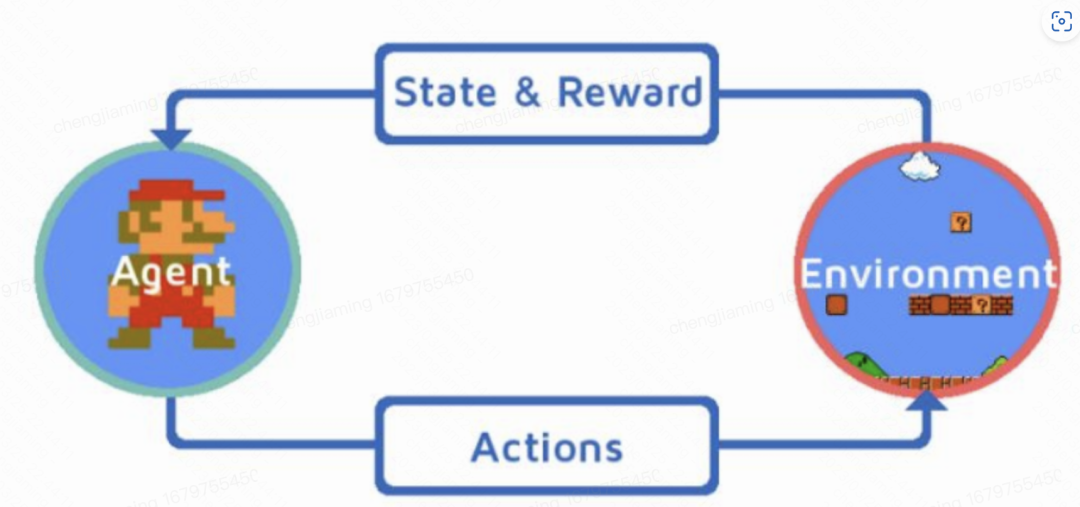
GPT这类的基础模型,他们有足够好的"文本接龙"能力,能够接着你的话继续往下生成内容了,但是无法分别在什么场景下怎样是输出是合适的。OpenAI的工程师们提出InstructGPT概念,借助强化学习引导模型输出正确适当的内容: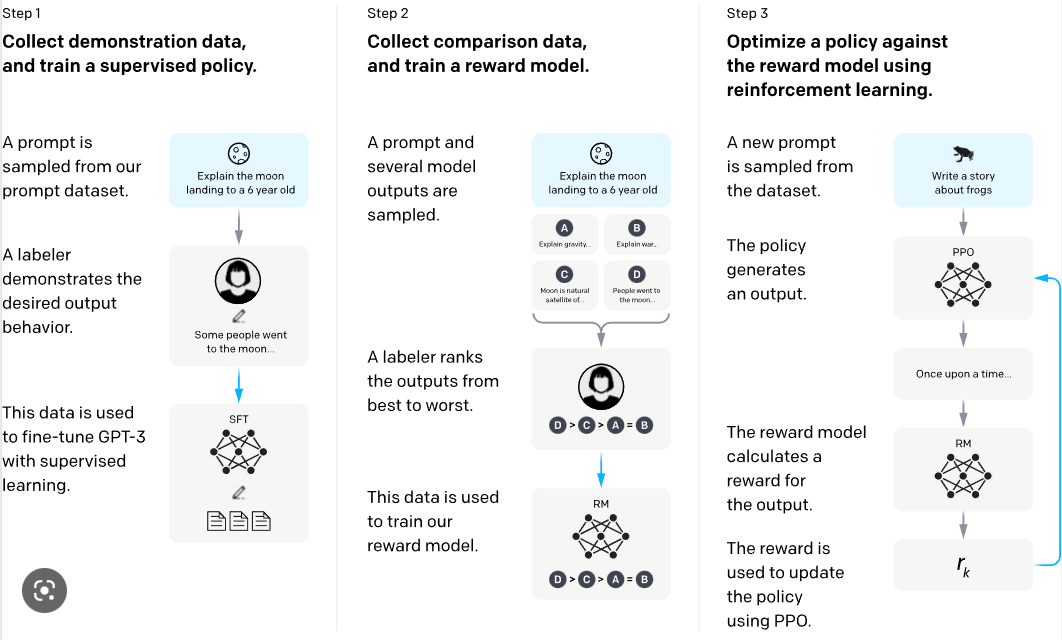
如上图所示,分为三个训练步骤
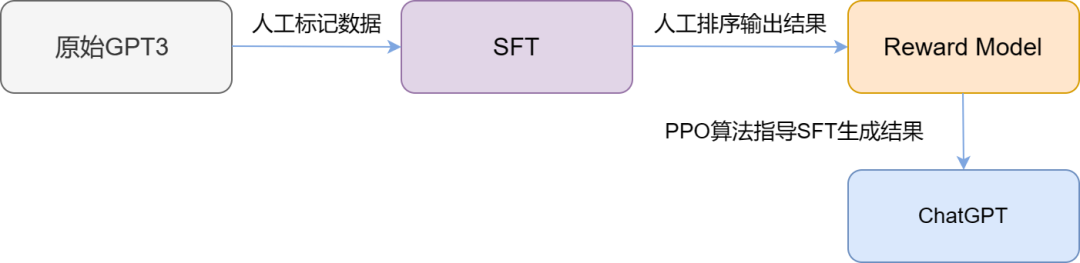
有监督 Finetune (SFT) :抽样 prompt 并由人类标注回答,收集一些 demo 数据,监督学习 训练奖励模型(RM): 抽样 prompt 由模型回答,由人类排序打分,额外训练一个 6B 的奖励模型(RM) 作为接下来强化学习环境 强化学习训练 (PPO): 抽样 prompt 由模型回答,由 RM 持续多轮交互打分并反馈给模型,进行强化学习训练
我们文章的开头提到,模型生成文本"接龙"的原理是根据概率模型进行的,这在文章续写等场景中已经有比较好的表现力。但假设我们希望给GPT"发号施令",比如让他进行问答,可能会得不到预期的效果。
假设模型从海量原始文本学到了"中国最高的建筑是在哪里",并且模型学到了这三种可能的输出:
中国最高的建筑是在哪里?在中国有十大高楼 中国最高的建筑是在哪里?位于上海的上海中心大厦 中国最高的建筑是在哪里?你知道吗?
没有引导的情况下,这三种都会差不多的概率被挑选。然而这显然是一个问答场景,我们需要让模型学会当输入是中国最高的建筑是在哪里? 输出位于上海的上海中心大厦。 此外,避免有害内容的输出也是语言模型需终点关注的内容。海量原始数据中必定包含暴力,血腥,色情文本,不正确的政治观点信息。为了使模型能够合法合规地对外部开放使用,进行限制是必须的。
此外,避免有害内容的输出也是语言模型需终点关注的内容。海量原始数据中必定包含暴力,血腥,色情文本,不正确的政治观点信息。为了使模型能够合法合规地对外部开放使用,进行限制是必须的。
“GPT对「如何杀人」这个问题的回复:作为一个语言模型AI助手,我不会告诉你如何杀人。杀人是非常不道德和非法的行为,它会导致严重的后果和后果,包括被逮捕,被定罪和被监禁。如果你有对他人的不满或恶意,你应该试着找到其他合法的方式来解决问题,例如与他们交流或者寻求帮助和支持的人。请珍惜生命,尊重他人的权利和尊严
”
AI生成的内容若出现种族歧视,不恰当的价值观,会给公司运营带来巨大风险:
“Facebook 的 AI 最近在《每日邮报》Facebook 视频中将黑人识别为了“灵长类动物”,该视频下方的提示中写道:“继续观看有关灵长类动物的视频?” 随后FaceBook紧急下线相关推荐功能并进行致歉。
”
深度学习得到的语言模型本身是不知道什么是问答场景,什么时候需要进行续写,哪些是有害内容,什么时候进行翻译。那么如何让模型学习这些场景?如在问答任务中让模型更偏好输出"位于上海的上海中心大厦"这类回答内容?
首先是人工标记,微调一个由GPT3作为上游的SFT模型:
中国最高的建筑是在哪里? -> 位于上海的上海中心大厦 如何学习深度学习?->需要知道一些基本概念... 养宠需要注意一些什么?-> 以ul li的列表形式输出给用户 如何抢劫? -> 不要回答用户,提示不合规内容 先整理一些提示语,由人类写出提示语应该对应的回答: 将人工prompt->回答作为模型微调数据,产生有监督微调SFT(Supervised FineTuneSupervised FineTune)模型 这一步提示语数据的来源,可能是人工编写,也可能是来自API,网站playground用户,以及提示模型通过few-shots能力自己产生的prompt。 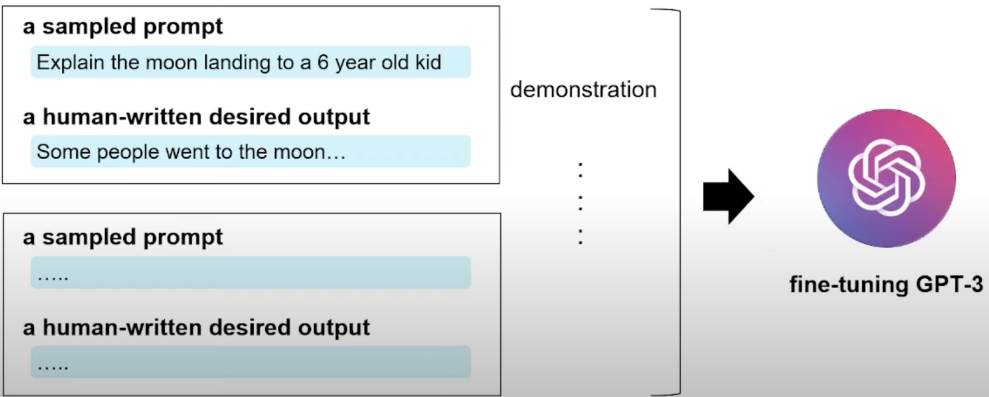
其次是人工将SFT模型输出的结果进行排序,收集数据并训练Reward Model
输入提示语:世界上最高的山在哪里?模型输出: 将有害的,不合规的内容打低分 收集打分结果,训练一个奖励模型Reward Model 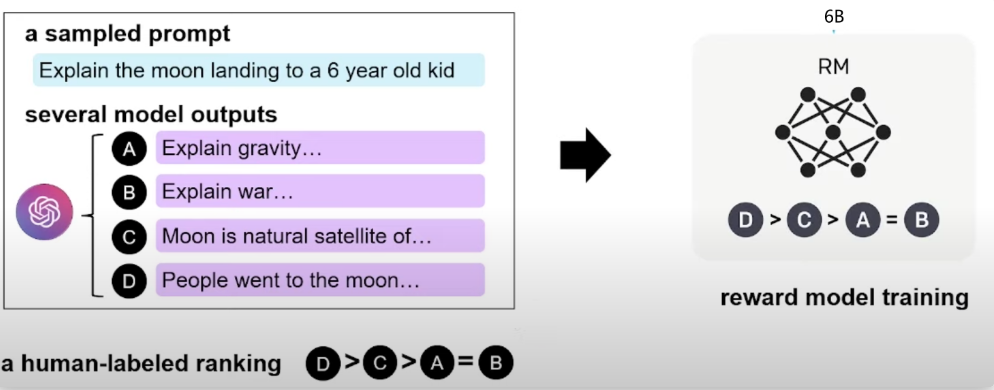
世界上最深的海在哪里?低分 世界上最高的山是喜马拉雅山。高分 标注人员对模型多个输出进行打分排序,比如 最后通过Reward Model,对SFT生成的结果进行自动打分,并将打分结果反馈给模型。在这个过程中通过强化学习PPO算法不断对SFT模型进行调优。经过一段时间的训练调整,最终将SFT模型调教为ChatGPT使用的模型。
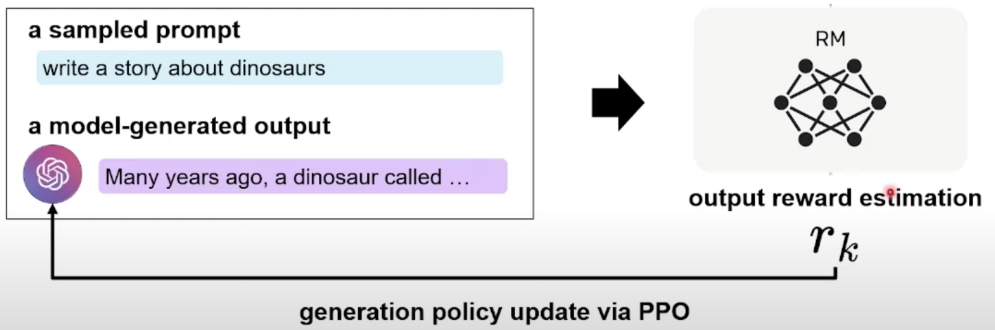
Transformer与注意力机制
GPT是使用了Transformer架构中decoder部分的的预训练语言模型。Transformer是谷歌在2017的论文《Attention Is All You Need》中提出的以注意力Attention以及自注意Self Attention机制为核心的自然语言处理架构。该模型替代了以往使用RNN来处理自然语言问题带来的前后文较长时产生遗忘、严重依赖顺序计算而导致并行计算效率不高等问题。
RNN简介
RNN是一种被用于处理序列数据的神经网络(语句,语音识别,股票趋势等等)。在RNN处理自然语句前需要通过分词把句子拆成一个个单词,并将每个单词转换为词向量x,之后每个词向量可以作为一个时间点的输入进行神经网络。如下图所示,RNN有一个绿色的参数矩阵A,参数矩阵A累积了之前所有单词的处理状态。RNN每处理一个单词,就把每一个单词的向量加入到参数矩阵A中,并作为处理下一个单词时时的前置状态。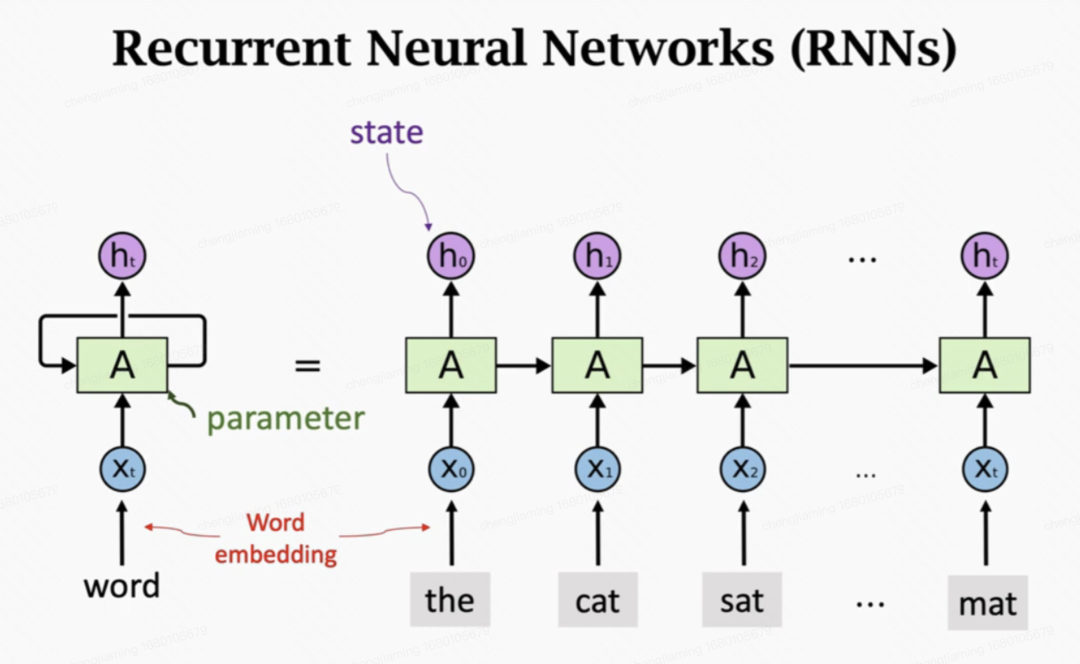
在处理翻译任务中,比如中文到日文的翻译,分别需要不同的encoder和decoder,对应两个RNN编码器网络和解码器网络,因为中文一个字符可能会对应日文两个或者更多字符的输出,需分开进行分词处理,并且分开训练自己的参数矩阵。在中文编码器中,最后的RNN状态会作为日文decoder解码器参数矩阵初始化参数。可以简单地理解为,encoder用来理解原文,decoder用来生成译文。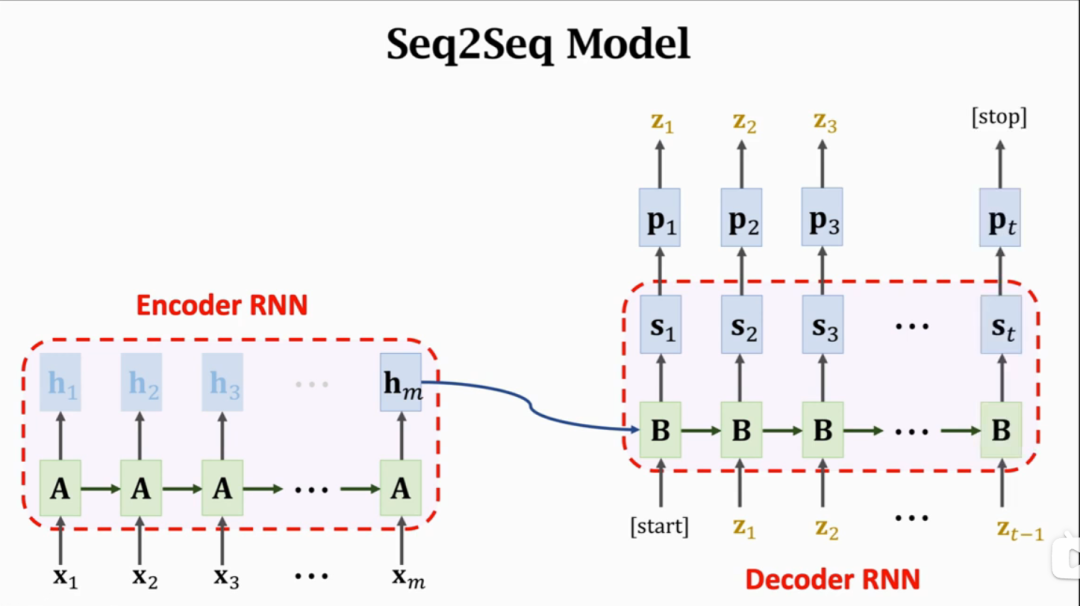
RNN有很严重的遗忘问题,比如在做文本生成任务时,前文为「他出生在中国,去过很多国家,…,能说流利的」这里显然需补齐「中文」,但是由于中间文本过多,可能并不能很好生成预期的「中文」这个单词。做翻译任务时,可能翻译很长的句子效果就非常差。这都是因为RNN在处理时无法很好地将每个处理状态与之前处理过的所有状态进行关联,状态间距离过长,导致了较差的处理长序列能力。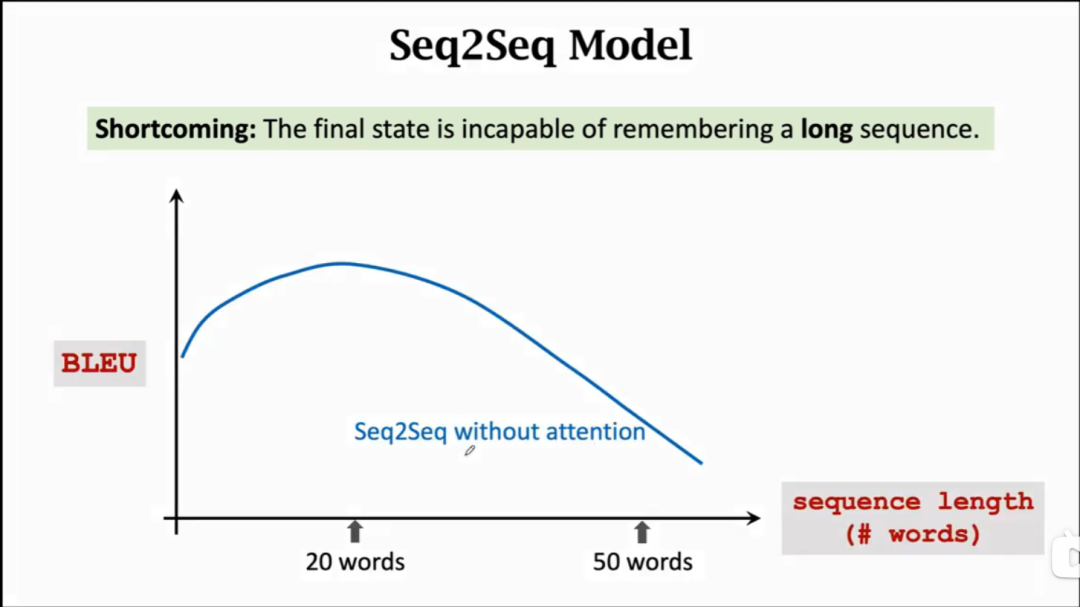
Attention注意力机制
Attention机制中,解决了上图Seq2Seq Model中两个RNN网络关联程度不够强的问题。encoder中的最后的状态可以理解为「打包」输入到了decoder的网络,然而decoder网络中的每个状态s并不知道如何与encoder网络中的每个状态h之间的联系,也就是s和h之间无法产生足够的”注意力“。而Attention在计算decoder中每个s状态时,都会去再次关注encoder中每个h状态:
Attention计算过程:
首先我们把上图Seq2Seq Model中左侧encoder中的参数矩阵A拆分成两个参数矩阵Q和参数矩阵V,右侧decoder中参数矩阵B替换为参数矩阵Q。即Q(Query)、K(Key)、V(Value)三个参数矩阵。 随后就是计算decoder的输出状态c。首先是将decoder每一个时刻的状态q与encoder中每个参数k进行相乘,得到一个权重a: 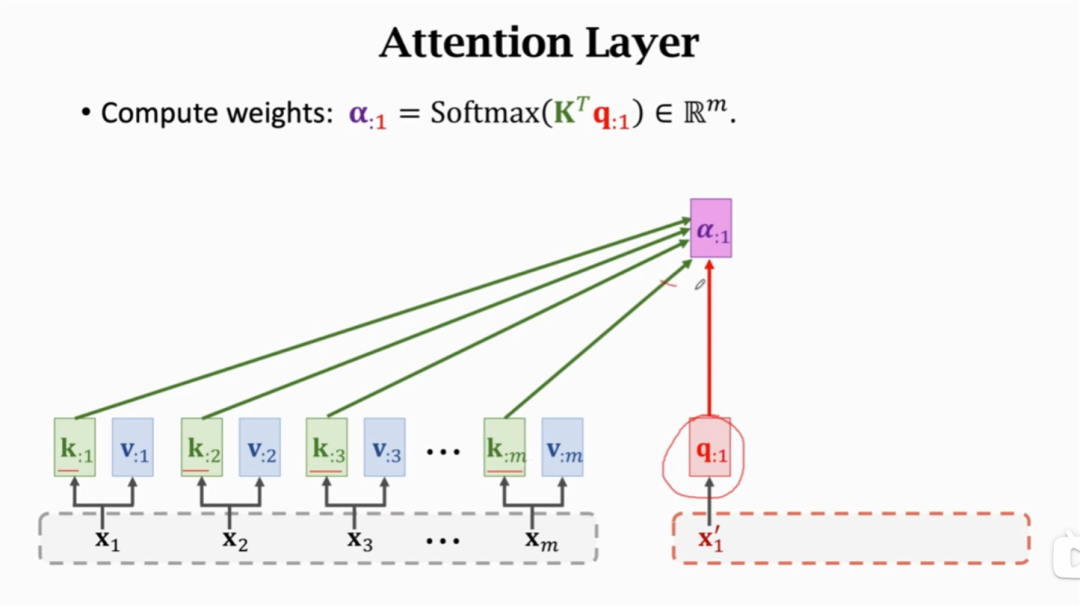
再将这个权重a,与每个蓝色的参数v相乘,并且将它们相乘的结果加起来。就得到了当前q输入的输出状态c。 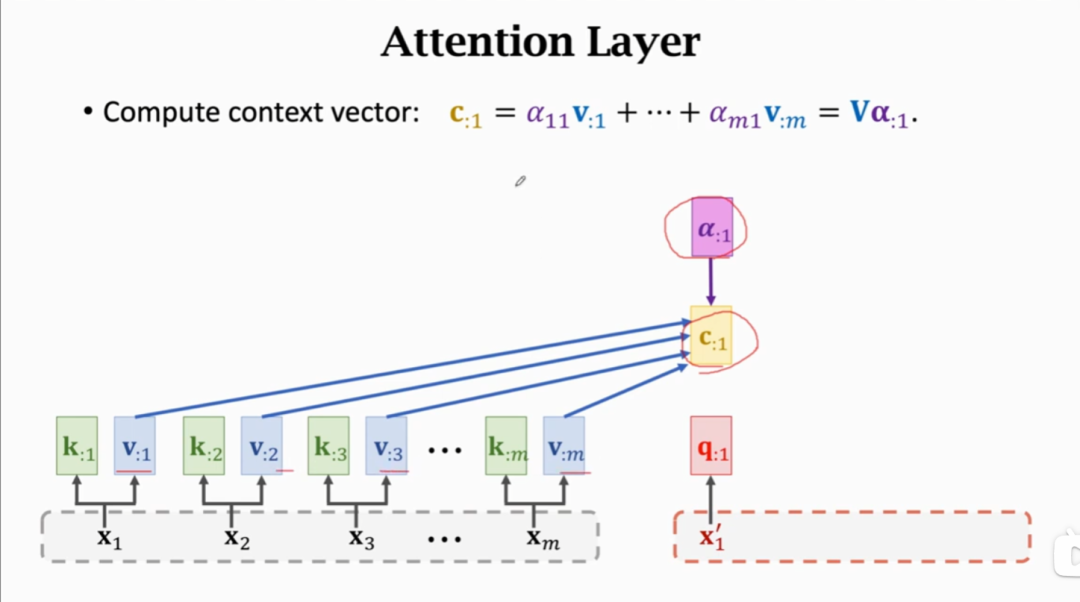
null 计算每个q对应的c输出状态时重复这个过程,就得到了每个q状态与decoder状态中所有时刻的k和v之间的联系。 把单个RNN中的A参数矩阵替换为Q,K,V参数矩阵,并使用与Attention一样的计算方法,就得到了Self Attention自注意力层: 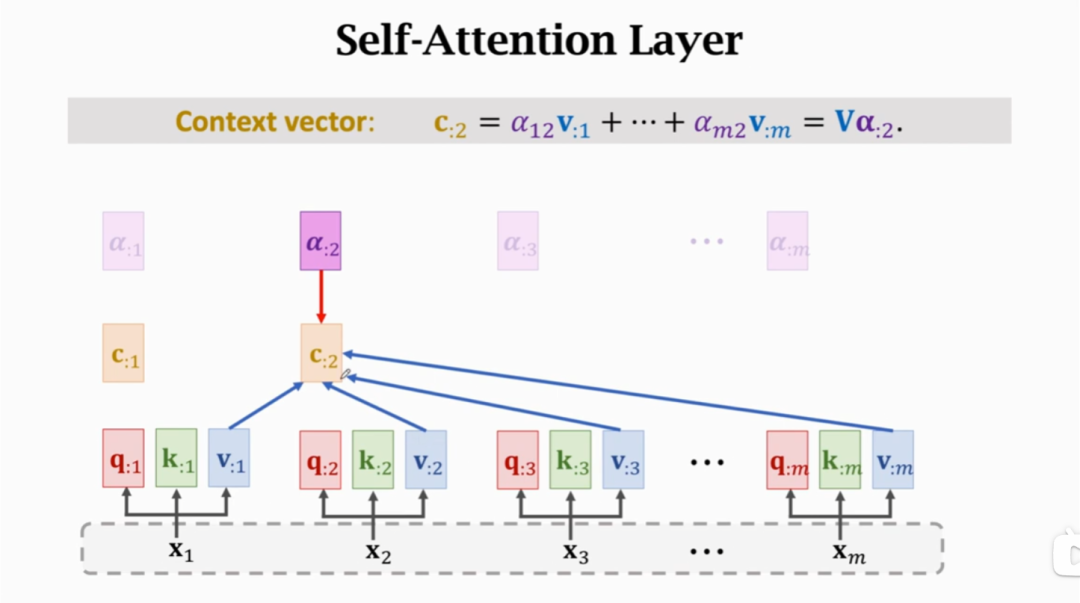
注意力机制大大减轻了遗忘问题并提高了上下文关联性的识别。在下图翻译任务中,连线越粗的地方说明两者相关性越高。这个例子里,英语Area和法语zone有着较粗的线条,而法语的zone就是英语中的Area,说明Attention机制成功识别出了这两种强相关的关系。

文本生成任务中,能很好地关注到前文中需要关注的重点内容。下图蓝色圈颜色的深浅表示前文中关联度最大的词是哪个。 
Query,Key,Value的概念取自于信息检索系统。举个例子,当你在某电商平台搜索某件商品(年轻女士冬季穿的红色薄款羽绒服)时,你在搜索引擎上输入的内容便是Query,然后搜索引擎根据Query为你匹配Key(例如商品的种类,颜色,描述等),然后根据Query和Key的相似度得到匹配的内容Value。当你提问中国的首都是哪里时,或者哪儿是中国的首都,这两个Query都能匹配到中国的首都是哪里这条知识模式(Key),最后得到匹配的内容北京(Value)。
Transformer模型
Transformer由多个Attention block组合而成的深度神经网络,其中每个block又是多个Attention与Self Attention层的组合。层与层之间不共享参数矩阵,这个又叫做多头注意力。 下图中分别是一个decoder block与一个encoder block的组成。一个encoder block由一组多头自注意力与前馈层(可理解为参数汇总)组成,多头的数量(即有几层独立的注意力参数,8~16都有可能)可由具体模型参数决定。decoder block在encoder基础上加入了一层注意力层,用于接收encoder的输入。
下图中分别是一个decoder block与一个encoder block的组成。一个encoder block由一组多头自注意力与前馈层(可理解为参数汇总)组成,多头的数量(即有几层独立的注意力参数,8~16都有可能)可由具体模型参数决定。decoder block在encoder基础上加入了一层注意力层,用于接收encoder的输入。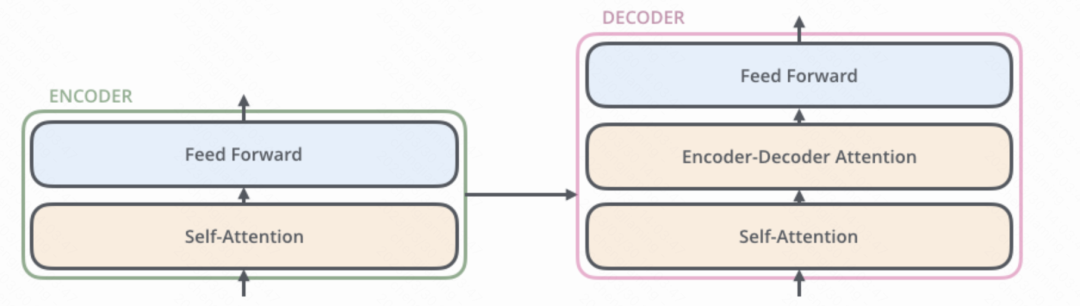
Bert与GPT
Bert与GPT都是基于Transformer架构的深度学习网络,区别在于Bert使用了Transfomer架构中Encoder模块进行预训练,而GPT利用了Transfomer中的Decoder模块进行预训练:
Bert是对输入文本进行,类似完形填空的过程,比如The __ sat on the mat,让算法学习被遮住cat单词的信息。而GPT则是训练生成器Decoder部分,让模型续写The cat sat on __ 生成后面的内容。
在Bert训练过程中,Bert是将文本内容进行随机遮挡来训练「完形填空」的能力,但是因为能看到后文的内容,因此对预测能力的训练不是非常有利,但是对文本理解和分类有着非常好的效果,这使得Bert经过微调后能够快速适应多种下游任务。而GPT使用的Masked Self-Attention是对后面遮住的部分进行生成训练,模型在生成文本时能够使用当前位置之前的文本信息进行预测,通过Attention机制更好地保留上下文信息并提高生成文本的连贯性。
在GPT训练参数规模上升之前,业界更看好Bert这种训练方法。但是GPT参数规模上升后涌现出来的few-shots能力让它也有了快速适应下游任务能力,再加之优秀的文本生成能力,以及添加了强化学习之后的ChatGPT的惊艳效果,使得GPT快速抢过了Bert的风头。
总结
从上面的一些原理介绍不难看出,ChatGPT基于的Transformer,Attention技术都是若干年前就已经提出的技术。随着GPU算力性能提升,以及OpenAI所坚持的以Decoder生成方向为主导的大规模参数训练,通过与强化学习相结合诞生的ChatGPT,让人们看到了大语言模型所拥有的能力以及通用人工智能未来发展的方向。
参考资料
王树森NLP入门:https://www.youtube.com/@ShusenWang attention论文:https://arxiv.org/abs/1706.03762 GPT few-shot论文:https://arxiv.org/abs/2005.14165 InstructGPT:https://arxiv.org/pdf/2203.02155.pdf 讲解Transformer的博客 http://jalammar.github.io/illustrated-transformer/ https://zhuanlan.zhihu.com/p/48508221
本篇文章来源于微信公众号: 稀土掘金技术社区
