


从GPT1到GPT4

AI发展史上很疯狂的一段时间

从去年年末ChatGPT出来到现在算的上是AI发展史很疯狂的一段时间吧,说实话没想到ChatGPT会如此出圈并打破Tiktok创造的最快用户增长的记录,ChatGPT和GPT4.0带来了很多惊喜,不过我想吐槽的是这更新速度也太快了,ChatGPT,LLAMA,Standford Alpaca,VisualGPT,ToolFormer,GPT4 ...,根本看不完啊。
这篇文章是我在实习期间看Openai官方发的GPT系列的技术报告整理的,主要想看些工程细节,顺序是GPT1 -> GPT2 -> GPT3 -> InstructGPT -> GPT4,因为是在研究所里看的并且做了ppt,所以语言文字可能并不会生动有趣哈,本来想在语言上再润色下的,但一方面是懒,另一方面手头有两个很有趣的项目(一个text2image,一个是做决策的大模型),如果做出来了效果好的话,我再给大家讲讲那两个吧,另外想要详细了解transformer的话可以看这篇Transformer笔记,那就开始吧。
GPT1
Improving Language Understanding by Generative Pre-Training
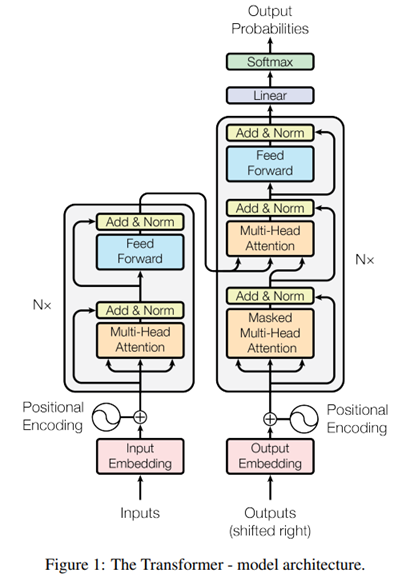
模型结构
GPT采用了Transformer的Decoder部分,12层自注意力模块,12个注意力头,每个注意力头的维度是64,position-wise feed-forward networks的中间隐藏层维度是3072。
GPT用的是Transformer的Decoder,Bert用的是Transformer的Encoder,区别在于Encoder能看到整个序列的所有元素,但对Decoder来说因为有mask(被mask掉的地方注意力分数为0)的存在,它只能看到当前元素和他之前的那些元素。
Step1: Unsupervised pretraining
训练的目标是根据前k个token预测下一个token,即给出一段语料,训练一个语言模型最大化下面的似然:
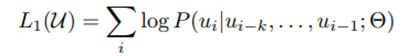
Step2: Supervised fine-tuning
假设有一个labeled dataset,dataset的instance是一段序列x_{i}, ... , x_{m}和label y,序列直接输入模型得到最后一个transformer块的隐藏层输出,隐藏层输出再通过一个linear layer来预测y:
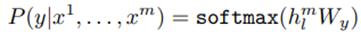
就得到了微调阶段的目标:
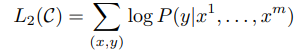
接下来就是如何把nlp的各种子任务表示成一个序列和一个对应的label:
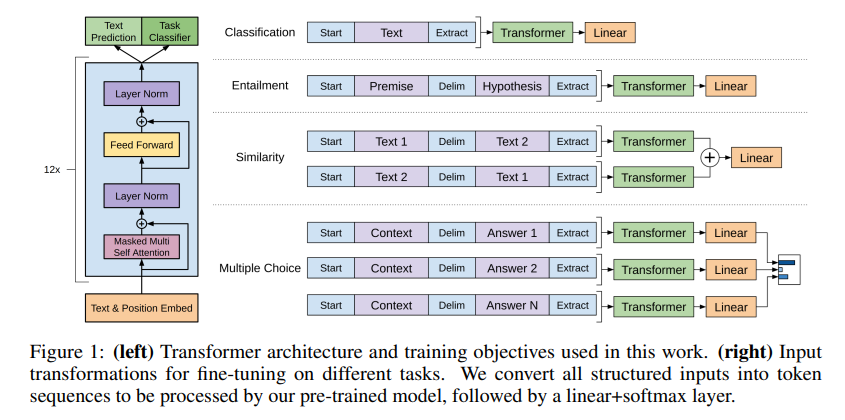
预训练和训练细节
预训练时使用Adam优化器,最大学习率为2.5e-4,warmup steps=2000,接着cosine方式衰减到0,batch size=64训练100个epochs,序列长度为512,embedding层和attention的dropout=0.1。
微调时,最后的classifier也设置了dropout=0.1,学习率=6.25e-5,batch size=32,仅训练了3个epoch,warmup steps=前0.2%steps,然后学习率线性衰减。
GPT2
Language Models are Unsupervised Multitask Learners
Zero shot
虽然相比GPT1,GPT2增大了数据集(Web Text)和模型参数(1.5B),但是却没有获得比小的多的BERT模型更多的提升,于是openai后面主要探讨了GPT2在不需要微调的情况下的Zero-shot的能力。之前主要是pre-training和supervised finetuning的组合,做下游任务的时候还需要对模型微调。语言模型并不需要supervised learning监督学习,unsupervised learning就可以学习多种任务。supervised learning的学习目标和unsupervised的学习目标是一致的,然而需要足够大的模型,并且这种方法要比监督学习各种任务慢很多。
zero-shot意味着在做下游任务的时候不需要下游任务的任何标注信息,所以在做下游任务的时候不能引入之前模型未见过的信息和特殊分隔符。一个翻译任务的zero-shot可以下面这样表示:*translate to French, English text, French text.*在网上爬取的更大的数据集中(清理后40GB左右)已经有了很多这样zero-shot的例子:

模型

GPT2的模型在GPT1的基础上做了一些修改:
将post norm变成了pre norm
在最后一个自注意力模块后又额外加了一个layer normalization
词表大小扩展到50257,context size从512提升到1024
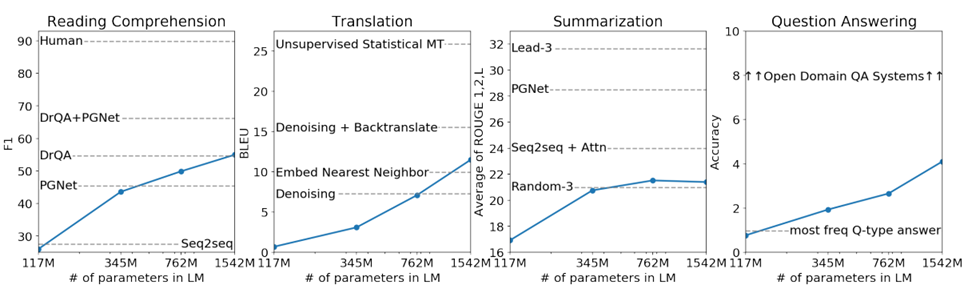
横坐标是GPT-2模型的参数量,可以发现随着参数量的提升,模型在各种任务上的表现仍然可以提升。
GPT3
Language Models are Few-Shot Learners
在大规模文本语料库上进行预训练,然后在特定任务上进行微调,可以在许多自然语言处理任务和基准测试中取得实质性的进展。但该方法仍需要成千上万个任务特定的微调数据集。相比之下,人类通常只需要几个示例或简单的说明就可以完成新的语言任务。
GPT-3展示了扩大语言模型的规模可以极大地提高无任务特定、少样本学习的性能,有时甚至可以达到优于先前最先进的微调方法的水平。OpenAI训练了1750亿个参数的GPT-3,然后在少样本学习中测试其性能。对于所有任务,GPT-3都不需要任何梯度更新或微调,任务和少量演示仅通过与模型的文本交互指定。
In-context learning和fine-tuning的不同在于,前者做各种任务时模型参数并不会更新。模型单纯依靠context来判断任务类型。
OpenAI探索了3种in-context learning,Few-shot,One-shot,Zero-shot,分别是提供少量演示,1个演示和不提供演示

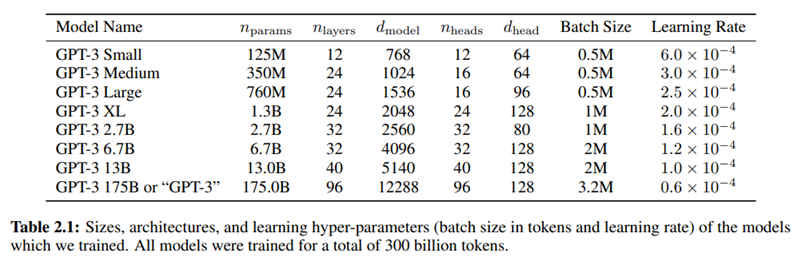
GPT-3的模型参数量增加到了1750亿,模型架构和GPT-2相同。为了研究模型大小对模型表现的影响,openai训练了8个不同大小的模型。
训练数据
为了能满足最大的模型的训练,GPT3使用了Common Crawl dataset,作者通过以下几步得到了一个更高质量的数据集:
GPT2训练的高质量数据集当作正类,Common Crawl爬取的低质量数据集当作负类,接下来对所有Common Crawl的数据分类,若分类器认为倾向于正类则留下
通过lsh算法去重
加入已有的高质量数据集来提升数据集的质量和丰富度
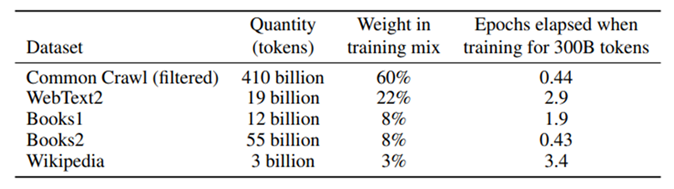
虽然common crawl的数据量要比其他数据集大几十倍,但因为数据质量较低所以训练过程中的采样率并没有那么高,当训练了300B tokens的时候,有的数据集已经被重复看了3次,有的还没有看完一次。
训练过程
最重要的没讲...
超参数
Adam优化器:β1 = 0.9, β2 = 0.95
梯度裁剪:clip_grad_norm = 1
学习率:linear warmup(the first 375 million tokens),然后以cosine decay方式衰减,衰减到到原来的0.1(260 billion tokens),接下来保持最初学习率的0.1继续训
gradually increase the batch size linearly
在每一个epoch中,data被无放回的采样,目的是减小过拟合
weight decay = 0.1
为了提升计算效率,训练过程中为最大序列长度(2048),如果序列短于2048则会将多个短句子拼接起来,不同的句子用一种特殊的end of text token隔开
有几个有趣或反经验的地方:
GPT3最大的模型batch size大小为3.2M,作者认为大批量计算性能会更好,每台机器的并行度更高,通讯量也会变低,小模型使用大批量过拟合会更加严重,相对来说大模型使用大批量降低模型的噪音,问题没有那么大。(为什么大batch size对大模型的影响较小)
随着batch size增大,学习率在逐渐衰减,而之前facebook的工作说随着batchsize增加学习率也要线性增加
模型评估
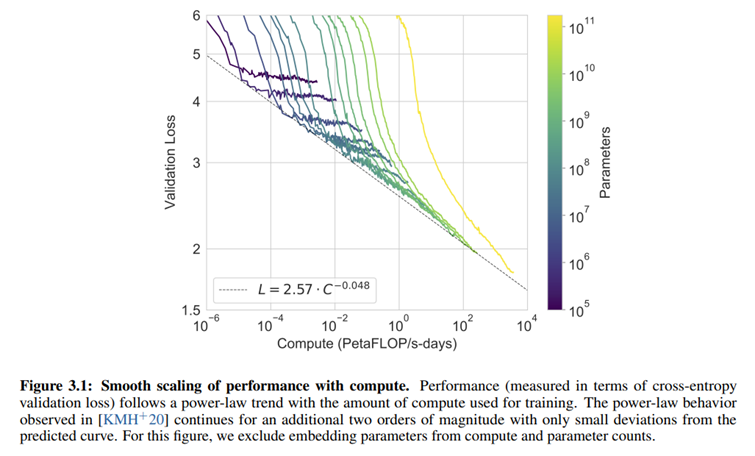
上图为不同参数量的模型的验证损失,发现随着计算量指数的增加,如果能找到一个合适的模型,即使没有过度训练,损失会线性下降。并且可以根据这个曲线来估计,如果想要想要降低到指定的验证损失,需要设计多大参数量的模型。
InstructGPT
Training language models to follow instructions with human feedback
大模型经常会表现出一些人类不想要的行为,比如捏造事实,生成有偏见和有毒的文本。根据网上的文本预测下一个词token和根据人类的指示instruction来生成有帮助和安全的答案是两个不同的目标函数,这篇论文展示了如何通过人类反馈来微调模型,使得模型输出和人类意图一致。
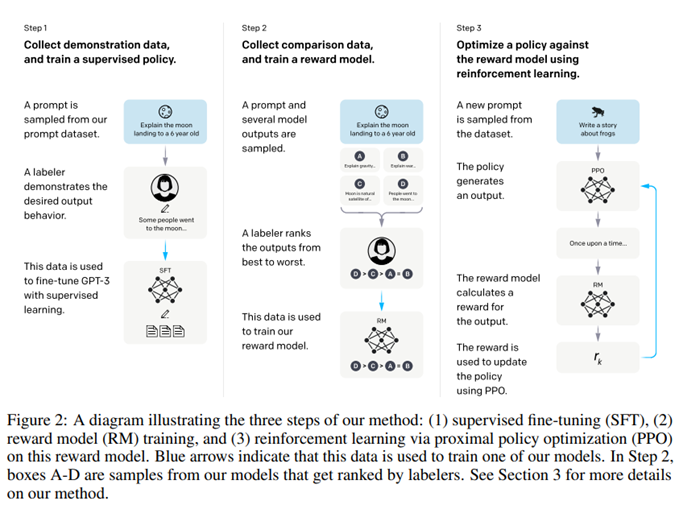
大概步骤:首先,openai标注了一个数据集,数据集中是openai收集的很多问题和标注者标注的这些问题的期待的模型输出,然后通过监督学习来对GPT-3做微调。
然后,openai又收集了一个数据集,对于一个问题,模型会有很多输出(可能是用了Beam Search的方法),标注者会根据模型输出的好坏排序,接下来训练一个奖励模型Reward Model,奖励模型会对模型的输出打分。
最后,模型根据prompt产生输出,奖励模型为输出打分,梯度下降更新策略模型。
Dataset
首先,openai让标注者写了很多问题,这些问题包括下面3种:
Plain:让标注者写任何问题,并且确保问题的多样性。
Few-shot:让标注人员写指令instruction,比如帮忙看代码bug,帮忙翻译...,以及这个指令的后续问题和回答。
User-based:用户想要通过openai api实现的应用。

然后,把模型放在playground里让大家用,openai又把这些问题采集回来做筛选,每个用户最多采用200个。从这些问题生成了3个不同的数据集,第一个数据集(13k大小)是标注者直接写答案来训练SFT model,第二个是RM dataset(33k大小)来训练奖励模型,第三个是PPO dataset,用来作为RLHF fine-tuning的输入。
其他细节:openai组织了测试来衡量标注人员的表现,最终筛选了40个合同工,并一直和这些标注人员保持了紧密的联系 。
在标注数据的时候。openai希望标注人员尽量把帮助性排在第一位,而在评测的时候希望把真实性和无害性排在第一位。
Step1 Supervised fine-tuning(SFT)
训练了16个Epoch,cosine learning rate decay,dropout为0.2,因为数据只有13000个,在1个Epoch后就过拟合了。但是这个模型并不会直接拿来用,而是用来初始化后面的RM模型和人类偏好评分的,所以过拟合是没有关系的,训练更多的epoch反而更有帮助。
Step2 Reward model(RM)
把上一个步骤得到的SFT模型的最后一层unembedding layer移除,训练一个模型,这个模型接受一个问题prompt和一个回答response,输出一个标量reward。(猜测是把模型最后的投影层和softmax层扔了,把输出的(b,l,d)展开后通过一了个输出大小为1的linear层)。作者仅训练了6B大小的RM,一方面是节省算力,另一方面是他们发现175B的RM训练起来不稳定。奖励模型的损失函数(Pairwise Ranking Loss):
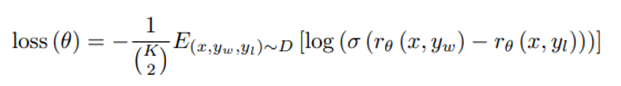
y_w是比y_l排序位置更高的response,所以希望r(x, y_w)-r(x,y_l)的差值尽可能大。若k=9,则可以选出36对(8+7+...+1),比k=4(6对)多了9倍,相当于数据集多了9倍,排序所花的时间可能只多了百分之几十,另外虽然损失函数是36项的损失,但实际上只要计算9次的前向和反向。
Step3 Reinforcement learning (RL)
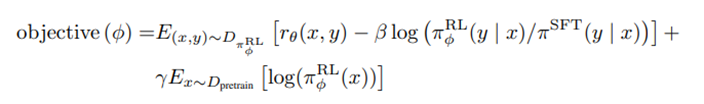
强化学习策略RL Policy由第一阶段训练的SFT模型初始化,模型输入问题prompt产生一个y,将(x, y)送入之前训练的奖励模型会得到一个分数r,然后梯度下降更新模型策略。
第二项有一个kl散度惩罚项,在训练奖励模型时,y来自于SFT模型,而我们现在做推理的y来自于RL策略新模型,随着训练进行,RL策略输出的y可能和训练奖励模型时输入的y发生偏移,导致奖励模型的估算没有那么准确,所以kl散度惩罚项的作用是希望强化学习策略新模型输出的y的概率分布不要和SFT模型输出的y的概率分布差太多。
第三项是为了防止新模型只在新的数据集上表现较好,而在原始GPT3预训练的数据集上性能下降,所以采样了部分原始GPT3的训练数据,gamma控制了要多偏向原始的GPT3。或许可以尝试在训练一段时间后,在新的RL策略下采样一些(x, y),然后再让标注员排序,然后再更新RL model。
Result
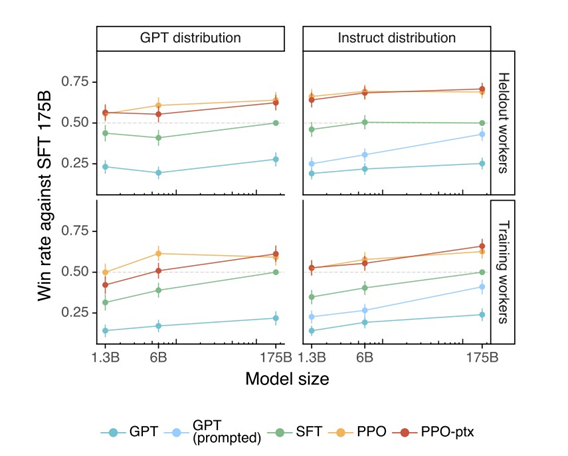
从上图中可以发现,经过新的数据集微调和强化学习训练后,即使是1.3B的模型表现也好于原始最大的GPT和只经过微调的GPT。
GPT4
GPT-4 Technical Report
GPT的模型训练分为两个阶段。首先,使用网上的大量文本预测下个单词,然后,用额外的数据对模型微调来生成人类评估者偏好的内容。第一个阶段给予了模型few-shot learning和执行多种自然语言任务的能力。微调阶段则使得模型的输出更加可控和有帮助。
GPT4是一个能处理文本和图像输入并输出文本的大型的多模态模型。
GPT4官方的技术报告主要讲了GPT4能干什么,局限性以及安全属性。考虑到竞争和安全因素,官方报告里不包含任何关于模型,硬件,数据集组成,训练方法等内容。
可预测的扩展性
GPT-4项目的一个重点是构建一个可预测扩展的深度学习堆栈(deep learning stack)。主要原因是对于像GPT-4这样的非常大的训练运行,进行大量的模型特定调优是不可行的。为了解决这个问题,openai开发了具有跨多个尺度的可预测行为的基础设施(infrastructure)和优化方法 (To address this, we developed infrastructure and optimization methods that have very predictable behavior across multiple scales.)。这些改进使得能够从使用少于1000倍-10000倍计算的小模型中, 可靠地预测GPT-4性能的某些方面。
1.损失的预测
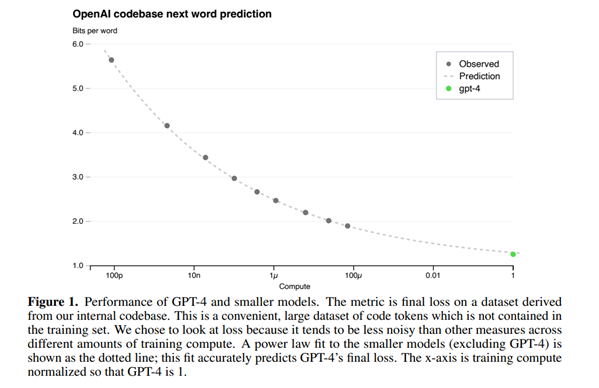
大型语言模型的最终损失 (final loss) 被认为可以通过用于训练模型的计算量的幂律(power laws)很好地近似。从使用相同方法训练的模型中预测GPT-4的最终损失,使用的计算量最多比GPT-4少10000倍。拟合的曲线准确地预测了GPT-4的最终损失。
2.人类评估测试的预测
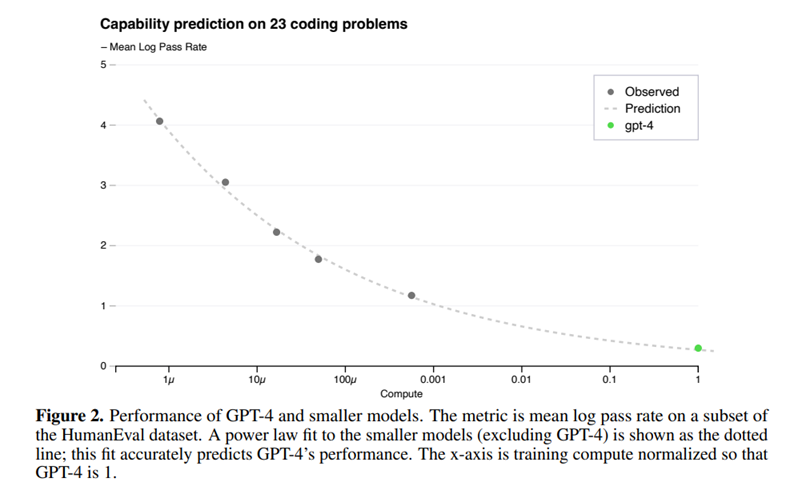
除了预测损失,openai还开发了预测更具解释性的能力指标的方法,即在HumanEval数据集上的通过率,它衡量了合成不同复杂性的Python函数的能力。通过从最多使用少1000倍计算的模型外推,成功地预测了HumanEval数据集子集上的通过率。
Safety
安全性上,openai的方法涉及结合模型层面的修改(例如训练模型拒绝特定请求)和系统层面(监控用户是否违反他们的使用政策)。在GPT4的预训练阶段,openai通过内部训练的分类器过滤了大量有害内容以及基于词典的方法来标记具有很高可能性的包含不适宜内容的文档,然后删除了这些文档。在之前的GPT模型中,openai通过人类反馈的强化学习(RLHF)来微调模型的行为来生成更符合人类意图的回答。然而在RLHF后,模型仍然有时在不安全的输入或安全的输入上表现出不想要的行为,并且模型会对一些安全的输入表现得过度谨慎,拒绝无害的请求。
1.改善模型拒绝的能力
GPT4的技术报告中对于安全的办法主要有两部分组成,safety-relevant RLHF training prompts和rule-based reward models (RBRMs).
rule-based reward models (RBRMs)是一组zero-shot的GPT-分类器。这些分类器会在RLHF微调中提供给GP4-policy model额外的奖励信号,比如拒绝生成有害的内容或者不拒绝无害的请求。
RBRM接受三个输入:the prompt(可选),policy model的输出,和一个人类写的说明(rubric,一系列规则,关于如何评估输出)。然后,RMRM会基于说明(rubric)对输出进行分类。比如可以通过提供一个说明(rubric)来指示模型将模型的回答划分为以下一类:(a) a refusal in the desired style(b) a refusal in the undesired style (e.g., evasive or rambling)(c) containing disallowed content(d) a safe non-refusal response在安全相关的training prompts里,如果GPT4拒绝了有害的请求,那么GPT4会得到奖励,如果GPT4没有拒绝那些安全且可回答(safe and answerable)的请求,那也会得到奖励。
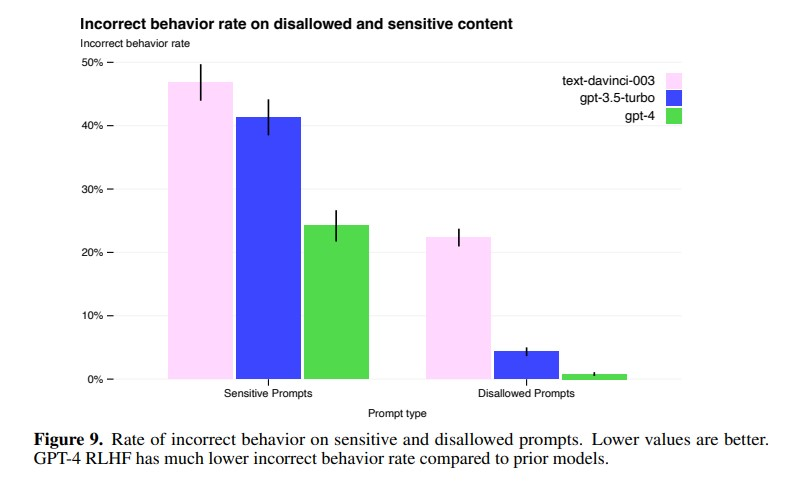
除此以外,openai还结合了别的改进方法,例如计算最优的RBRM权重和提供额外的想要在目标领域改进提升的SFT数据。这些方法使得GPT-4在安全性上相比GPT-3.5有明显提升。
2.减轻模型生成不真实内容的问题
openai也尝试干预模型来降低模型幻想(hallucinations)的频率,他们采用了两种方法:收集现实世界中用户使用ChatGPT时标记为“不是事实”的数据以及额外的标注的对比数据 通过以下步骤让GPT4自己生成对比数据
将一个prompt送入GPT4模型,然后得到一个response回复
将prompt+response送入模型并附带一条指示instruction,指示GPT4列出所有不真实的地方,如果没有的话则回到步骤1(送入新的prompt)
将prompt+response+hallucinations送入GPT4,并指示GPT4重写response without hallucinations
将prompt+new response送入GPT4模型并附带一条指示instruction,指示GPT4列出所有不真实的地方,如果没有发现则保留(original response, new response)的文本对;否则,重复上面步骤最多5次
这个过程会产生(original response with hallucinations, new response without hallucinations)的对比文本对,然后就可以把这些数据混入RM dataset了。
结果发现在TruthfulQA数据集上相比于早期版本有明显提升(30%左右)。
其他大语言模型
-END-
本篇文章来源于微信公众号: Yuan的学习笔记
