大型语言模型(LLM)正在改变每个行业的用户期望。然而,建立以人类语音为中心的生成式人工智能产品仍然很困难,因为音频文件对大型语言模型构成了挑战。
是的,处理长音频的问题是语音识别领域一直以来的难点之一。传统的语音识别系统通常使用窄带语音频率(8 kHz),因此在处理长音频时需要将其分割成多个短语音段进行识别。但这种方法会带来一些问题,比如断句不准确、上下文信息缺失等。
基于 LLM 的语音识别模型可以一定程度上解决这个问题。由于 LLM 可以学习长文本之间的关系,因此可以直接处理长音频并在模型内部进行对齐。但是,如何将长音频有效地输入到模型中仍然是一个挑战。
LeMUR 是一个很好的尝试,通过将长音频分别拆分成多个小片段,然后对每个小片段进行短时语音特征提取,并将特征序列输入到 LLM 中进行处理,以便处理长音频文件。与传统的分段方式相比,这种方式可以更充分地利用音频文件中的上下文信息,提高语音识别的准确度和连续性,同时也可以更好地应对长音频文件的处理问题。
当然,这种方式也需要一定的硬件和软件支持,如高性能 GPU、大内存、高效的分布式训练算法等。在实际应用中,还需要根据具体情况对模型进行优化和调整,才能达到最佳效果。
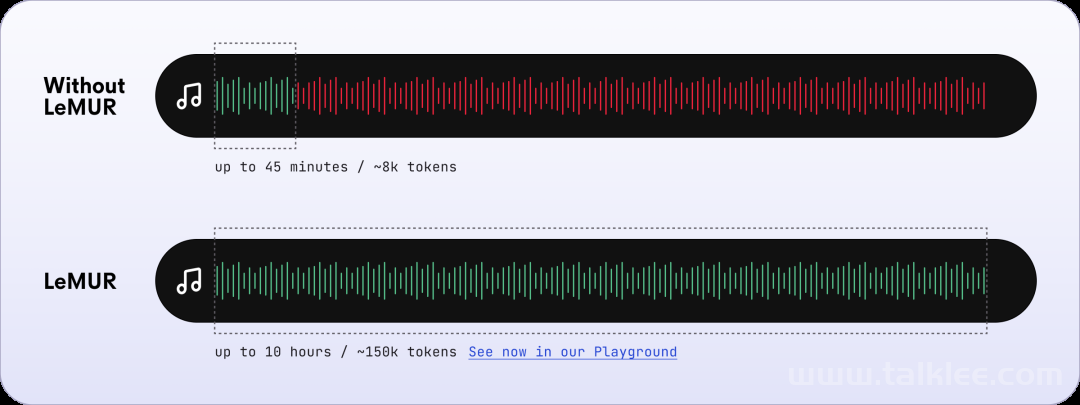
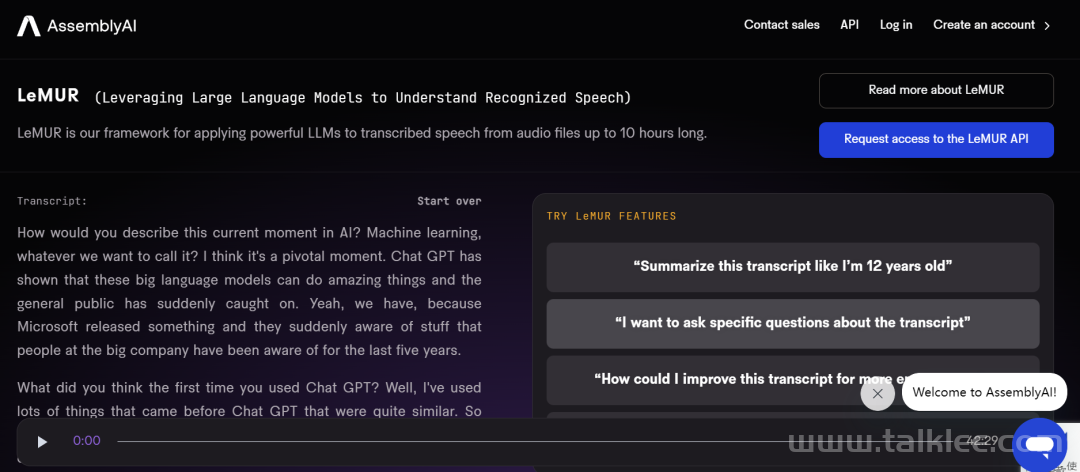
试用地址:https://www.assemblyai.com/playground/v2/sourceLeMUR 是 Leveraging Large Language Models to Understand Recognized Speech(利用大型语言模型来理解识别的语音)的缩写,是将强大的 LLM 应用于转录的语音的新框架。只需一行代码(通过 AssemblyAI 的 Python SDK),LeMUR 就能快速处理长达 10 小时的音频内容的转录,有效地将其转化为约 15 万个 token。相比之下,现成的、普通的 LLM 只能在其上下文窗口的限制范围内容纳最多 8K 或约 45 分钟的转录音频。为了降低将 LLM 应用于转录音频文件的复杂性,LeMUR 的 pipeline 主要包含智能分割、一个快速矢量数据库和若干推理步骤(如思维链提示和自我评估),如下图所示:
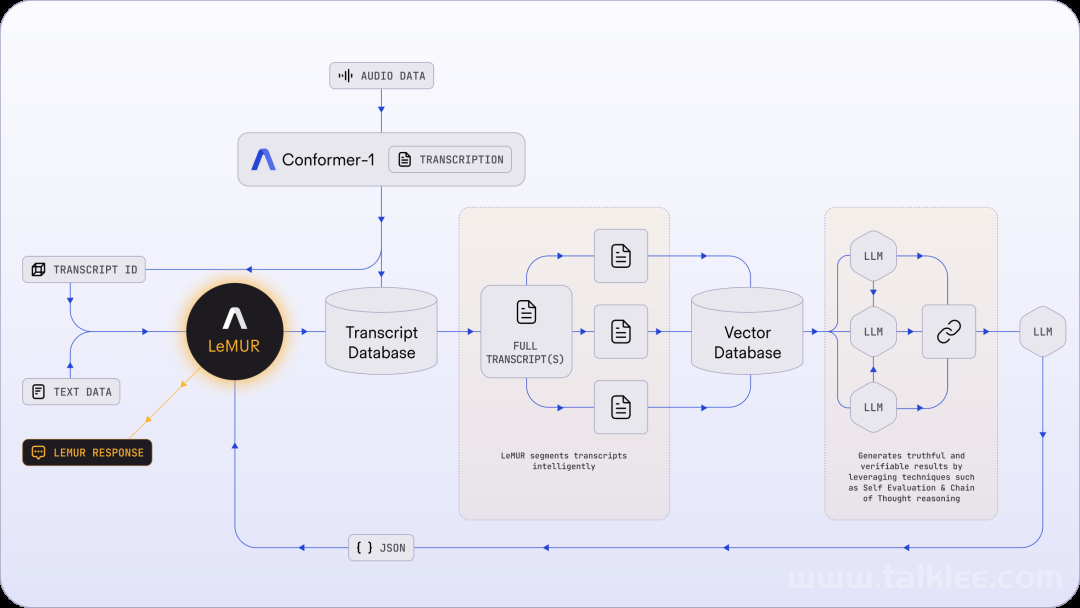
图 1:LeMUR 的架构使用户能够通过一个 API 调用将长的和 / 或多个音频转录文件发送到 LLM 中。

LeMUR 解锁了一些惊人的新可能性,在几年前,我认为这些都是不可能的。它能够毫不费力地提取有价值的见解,如确定最佳行动,辨别销售、预约或呼叫目的等呼叫结果,感觉真的很神奇。—— 电话跟踪和分析服务技术公司 CallRail 首席产品官 Ryan Johnson
LeMUR 解锁了什么可能性?
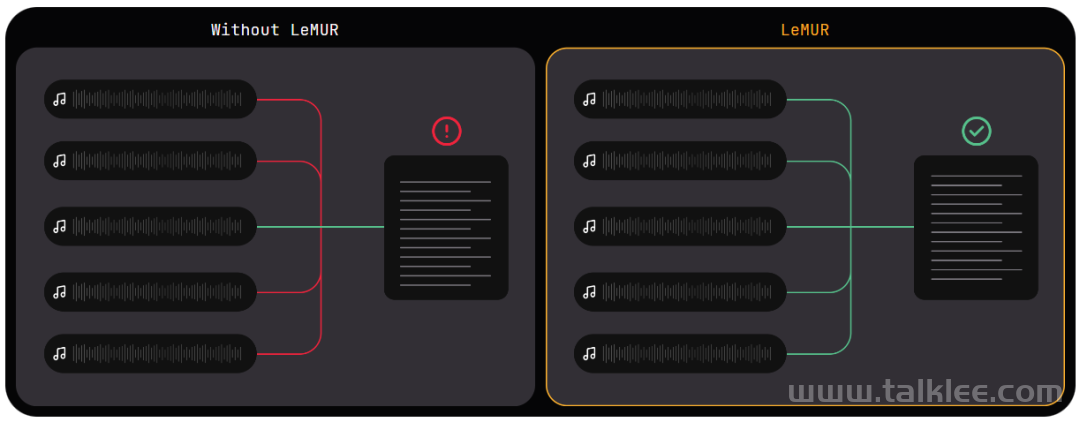
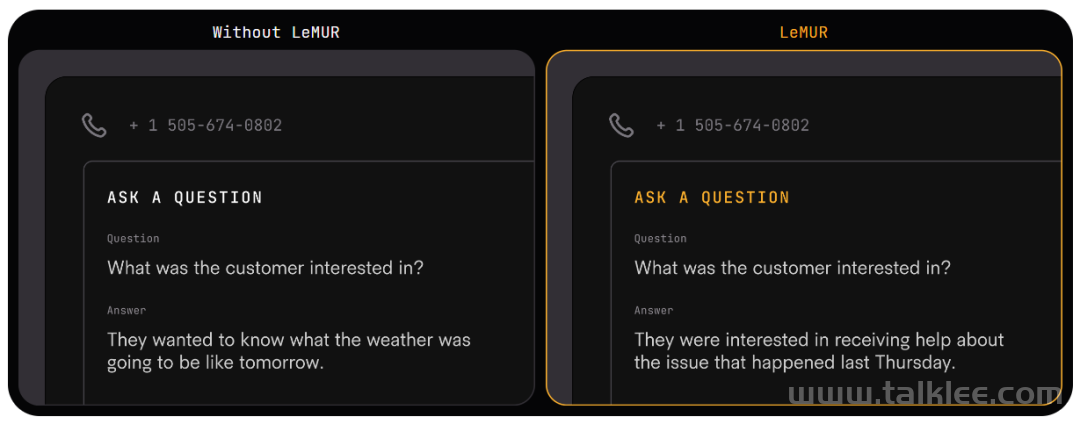
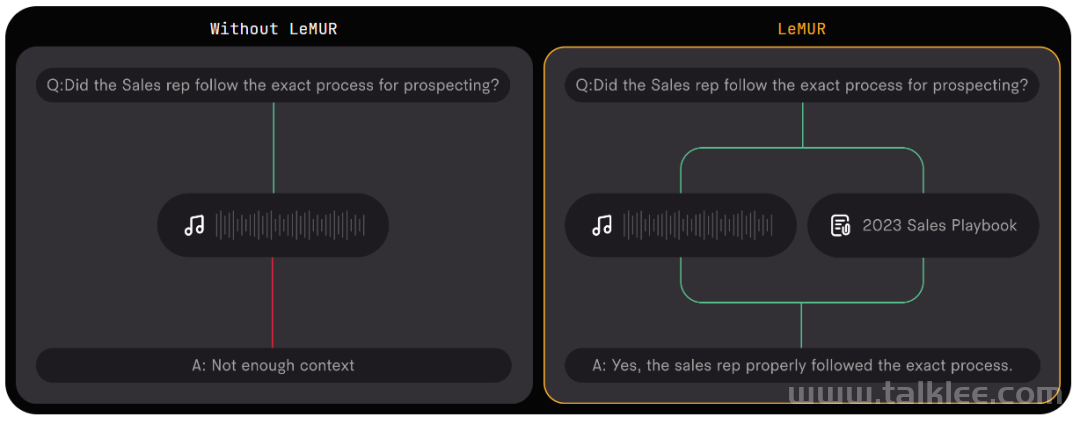
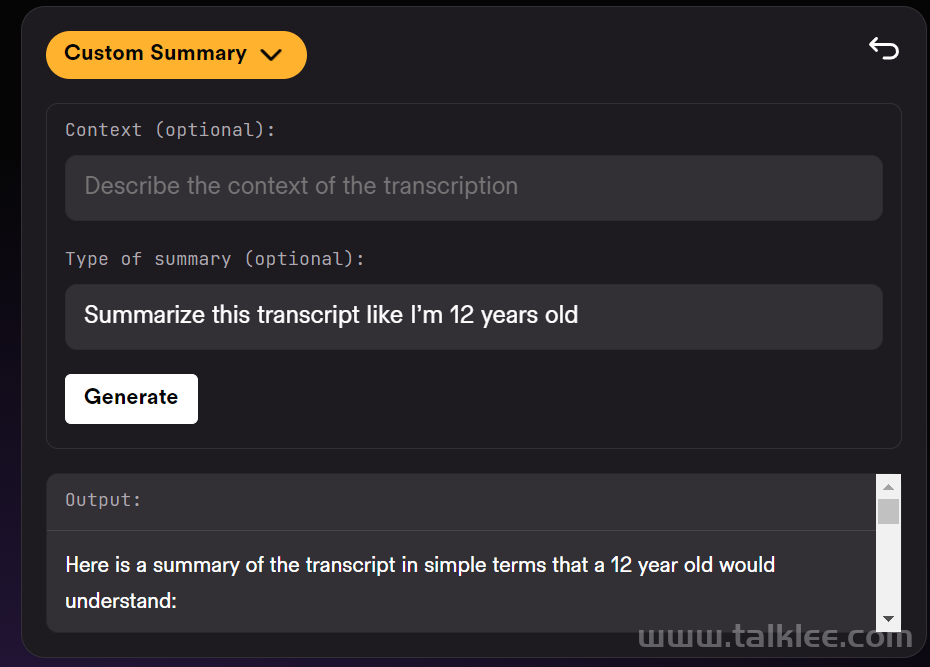
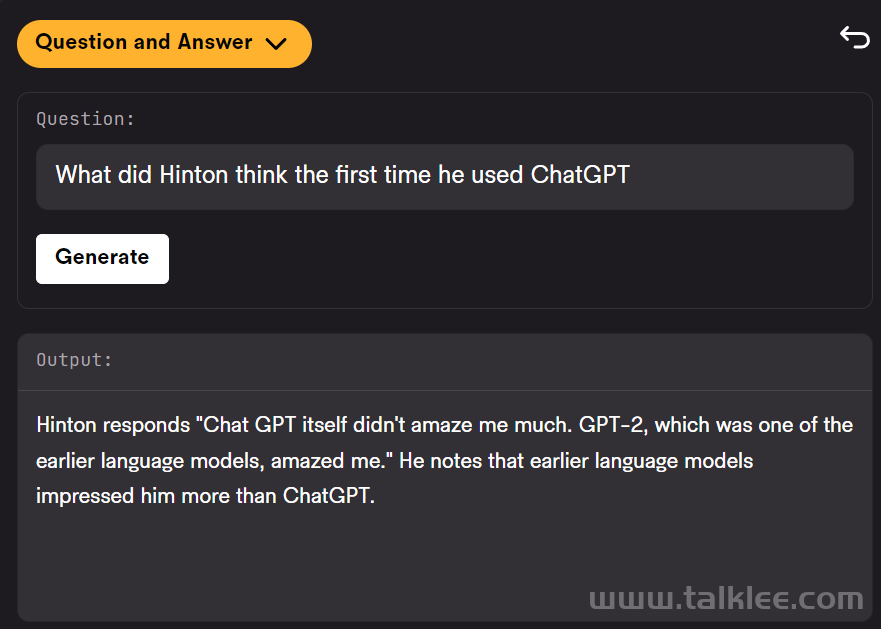
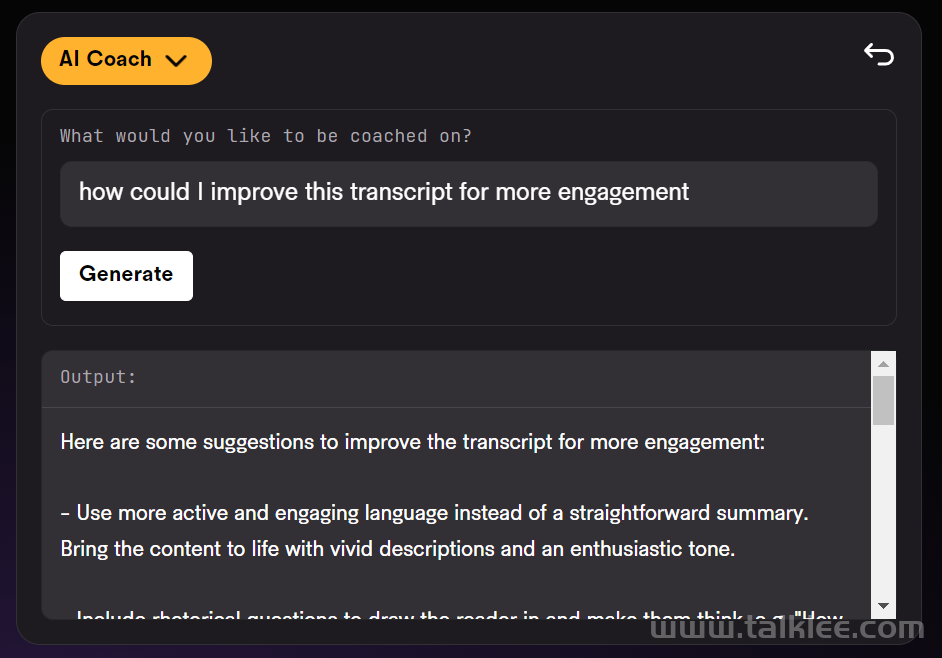
LeMUR 能够让用户一次性获得 LLM 对多个音频文件的处理反馈,以及长达 10 小时的语音转录结果,转化后的文本 token 长度可达 150K 。由于 LeMUR 包含安全措施和内容过滤器,它将为用户提供来自 LLM 的回应,这些回应不太可能产生有害或有偏见的语言。在推理时,它允许加入额外的上下文信息,LLM 可以利用这些额外信息在生成输出时提供个性化和更准确的结果。LeMUR 始终以可处理的 JSON 形式返回结构化数据。用户可以进一步定制 LeMUR 的输出格式,以确保 LLM 给出的响应是他们下一块业务逻辑所期望的格式(例如将回答转化为布尔值)。在这一流程中,用户不再需要编写特定的代码来处理 LLM 的输出结果。根据 AssemblyAI 提供的测试链接,机器之心对 LeMUR 进行了测试。LeMUR 的界面支持两种文件输入方式:上传音视频文件或粘贴网页链接均可。我们用 Hinton 近期的一份访谈资料作为输入,测试 LeMUR 的性能。上传之后,系统提示我们要等一段时间,因为它要先把语音转成文字。在页面右侧,我们可以要求 LeMUR 总结采访内容或回答问题。LeMUR 基本可以轻松地完成任务:如果要处理的语音是一段演讲或客服回复,你还能向 LeMUR 征求改进建议。不过,LeMUR 似乎目前还不支持中文。感兴趣的读者可以去尝试一下。